
Aus den Daten, die ein potenzieller Kunde (ein “Lead") auf einer Website hinterlässt, lassen sich wichtige Erkenntnisse über das Verbraucherverhalten gewinnen. Mithilfe des maschinellen Lernens wird dann aus diesen Informationen ein Vorhersagemodell erstellt. Die Erfolgsquote eines Vorhersagemodells liegt in diesem Beispiel bei 90%. Ein Bildungsunternehmen kann zum Beispiel Online-Kurse für Fachleute anbieten. Dank der Marketingaktivitäten besuchen täglich viele Interessierte die Website des Unternehmens. Auf diese Weise werden über Social-Media-Plattformen, Websites oder Suchmaschinen wie Google neue Interessenten angelockt. Nachdem sie auf die Website gelangt sind, sehen sie sich vielleicht Kurse an, füllen ein Formular aus oder sehen sich einige Videos an. Wenn sie die Website verlassen, ohne diese wichtige Aktivität abgeschlossen zu haben, werden sie umgeleitet und zur Konversion gedrängt. Wenn Personen ein Formular ausfüllen und ihre E-Mail-Adresse oder Telefonnummer angeben, werden sie als potenzielle Kunden eingestuft. Die Vertriebsmitarbeiter beginnen mit Anrufen, dem Versenden von E-Mails usw., sobald sie diese Leads erworben haben. Einige der Leads werden umgewandelt, während die meisten nicht durch dieses Verfahren umgewandelt werden. Eine typische Konvertierungsrate für Leads liegt bei etwa 30 %. Wenn zum Beispiel an einem Tag 100 Leads gesammelt werden, werden nur etwa 30 davon umgewandelt. Das Unternehmen möchte im Rahmen dieses Prozesses “heiße Leads" oder potenzielle Leads finden, um ihn effizienter zu gestalten. Wenn es gelingt, diese Leads zu finden, sollte die Konversionsrate steigen. Denn das Vertriebsteam ist nun mehr daran interessiert, mit potenziellen Kunden ins Gespräch zu kommen, anstatt jeden einzelnen anzurufen. Dies verbessert nicht nur den Verkaufsprozess, indem es ihn beschleunigt und seine Effizienz erhöht, sondern senkt auch die Personalkosten. Es liegt in unserer Verantwortung, ein System zu entwickeln, in dem jeder Lead einen Lead-Score hat. Kunden mit einem höheren Lead-Score haben eine größere Chance auf eine Konversion, Kunden mit einem niedrigeren Lead-Score haben eine geringere Chance auf eine Konversion.
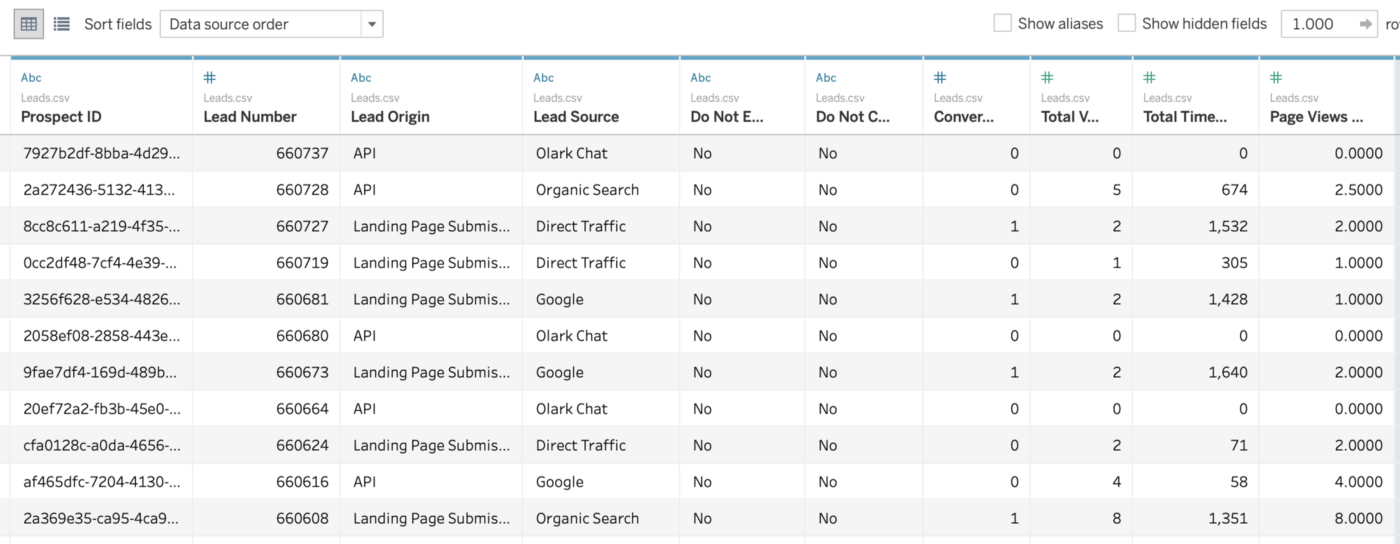
Wir verwenden in dieser Demo Daten von Kaggle. Kaggle ist eine Gemeinschaft von Data Scientists und Data Analysts, die an Data-Science-Problemen arbeiten. Die Teilnehmer posten Data-Science-Probleme, die sie von Data-Analysten und Data-Scientists lösen lassen möchten. Diese Data-Science-Probleme enthalten oft einen Datensatz. Kaggle ist ein hervorragender Ort, um mit dem Aufbau von Data Science-Fähigkeiten zu beginnen und Data Science-Probleme zu entdecken, an deren Lösung Sie interessiert sein könnten. Der Datensatz enthält die folgenden Informationen: Im Folgenden finden Sie einen Auszug aus den Daten. Es gibt 9240 Datensätze mit 37 Merkmalen für Personen. Jeder Lead hat seinen eigenen Satz von Merkmalen. Es gibt numerische Merkmale, wie z.B. die Verweildauer auf der Website, aber auch viele kategorische Merkmale, wie z.B. demografische Informationen und Informationen aus Webformularen.
In diesem Fall sind fehlende Daten ein Problem, das angegangen werden muss. Es ist keine gute Idee, alle unvollständigen Datensätze zu entfernen, da zu viele Datensätze gelöscht würden. Eine gründliche Untersuchung ist erforderlich. Datenanalysten verwenden in dieser Phase von Data Science-Projekten häufig Tools zur Bewertung der Datenqualität, um ihre Arbeit zu erleichtern und weniger zeitaufwändig zu gestalten. Wir werden also Merkmale mit mehr als 40 % fehlenden Werten entfernen, da es an dieser Stelle nicht viel zu analysieren gibt. Bei Merkmalen mit weniger fehlenden Daten werden diese durch den dominanten Wert des Merkmals ersetzt. Für viele Spalten des Datensatzes gibt es “Auswahl"-Werte. Diese Werte wurden von den Kunden bei der Eingabe angegeben, wenn sie keinen Wert aus der Liste im Formular auswählten (es könnte sein, dass dies keine Pflichtangabe war). In diesem Beispiel erscheint “Auswählen" im Datensatz. Da “Select"-Werte so gut wie NULLs sind, werden sie durch NULLs ersetzt. Kaggle hat eine ausführliche Anleitung dazu. https://www.kaggle.com/danofer/lead-scoring erklärt detailliert, wie man diese Schritte durchführt. Wir haben festgestellt, dass viele Merkmale keine Informationen zum Modell beitragen, also haben wir sie von der weiteren Untersuchung ausgeschlossen. Der Datensatz umfasst 16 Merkmale.
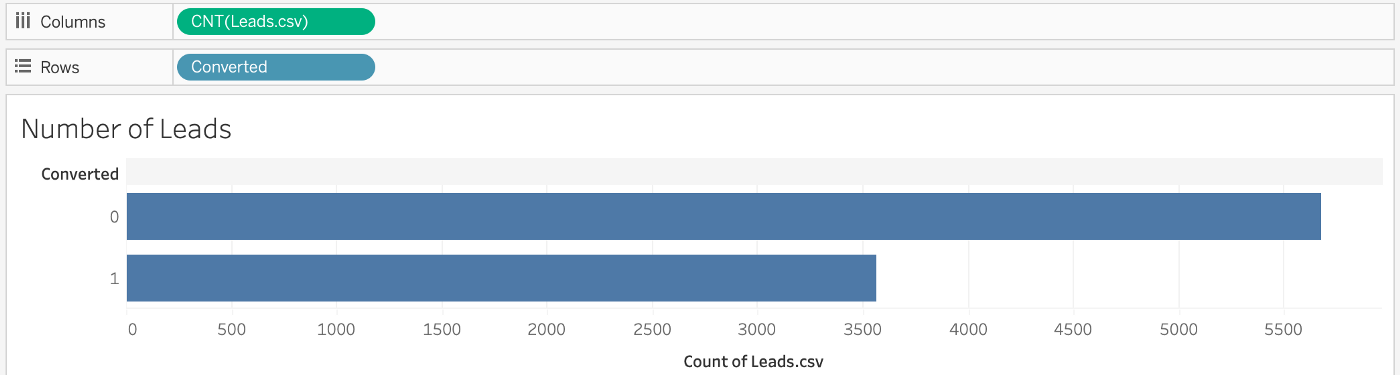
"Datenvisualisierung ist der beste Freund eines Datenwissenschaftlers, und Tableau ist eines der von Datenwissenschaftlern am häufigsten verwendeten Tools zur Datenvisualisierung." PROF. (FH) DR. ANDREAS STÖCKL Senior Expert Marketing Data Science Tableau ist ein Tool zur Datenvisualisierung. Eine gute Datenvisualisierung ist ein wichtiger Bestandteil der Datenwissenschaft. Data Scientists verwenden die Datenvisualisierung häufig im Prozess der Modellerstellung, um zu verstehen, welche Variablen wichtig sind und wie sie zusammenarbeiten können, um gute Modelle zu erstellen. Die Datenvisualisierung ist auch eine Schlüsselkomponente für Data Science-Präsentationen. Data Scientists und Datenanalysten erstellen häufig Datenvisualisierungen und Datengeschichten, um Data Science-Ergebnisse anderen Data Scientists, Datenanalysten, Geschäftsleuten, Käufern von Datenprodukten oder -dienstleistungen und Kunden zu vermitteln. Schauen wir uns an, wie viele Leads und Nicht-Leads es in unserer Fallstudie gibt, indem wir ein einfaches Balkendiagramm erstellen. Ziehen Sie dazu “Konvertiert" als Dimension auf “Zeilen" und die Anzahl der Leads auf “Spalten".
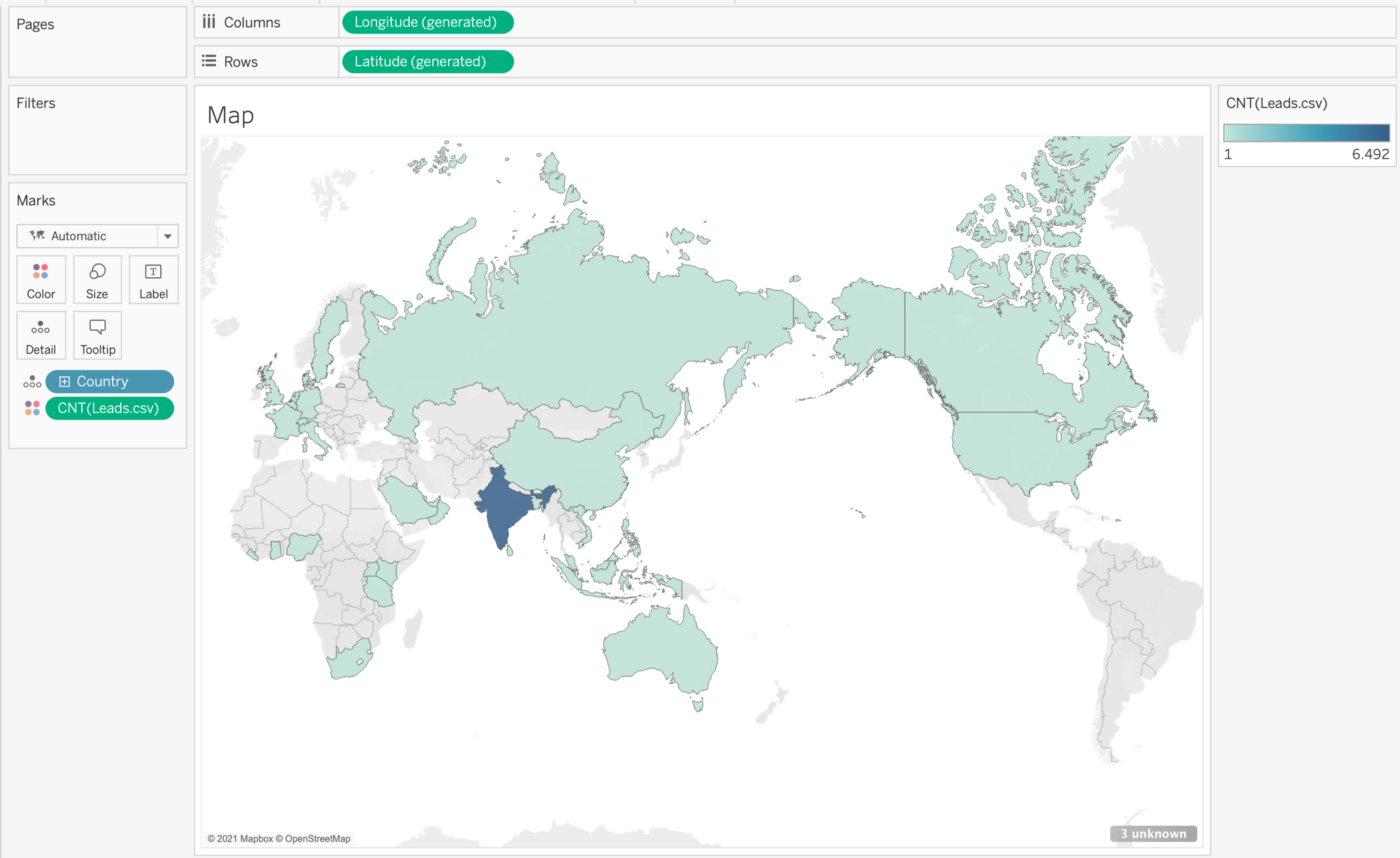
Das Merkmal “Konvertiert" wird auf 1 gesetzt, wenn ein Lead erfolgreich konvertiert wurde (38%), und auf 0, wenn er nicht konvertiert wurde (62%). In unseren Studien wurden 38% der Kunden akquiriert. Schauen wir uns nun die Verteilung der Daten auf der Welt an, indem wir eine Karte mit farbigen Ländern auf der Grundlage der Anzahl der Einträge anzeigen lassen. Dazu verwenden wir die Dimension “Land" und die Gesamtzahl der Leads zusammen mit dem entsprechenden Diagrammtyp. Tableau generiert dann Breiten- und Längengrad-Daten, die automatisch in “Zeilen" und “Spalten" in Ihrer Tabelle eingefügt werden.
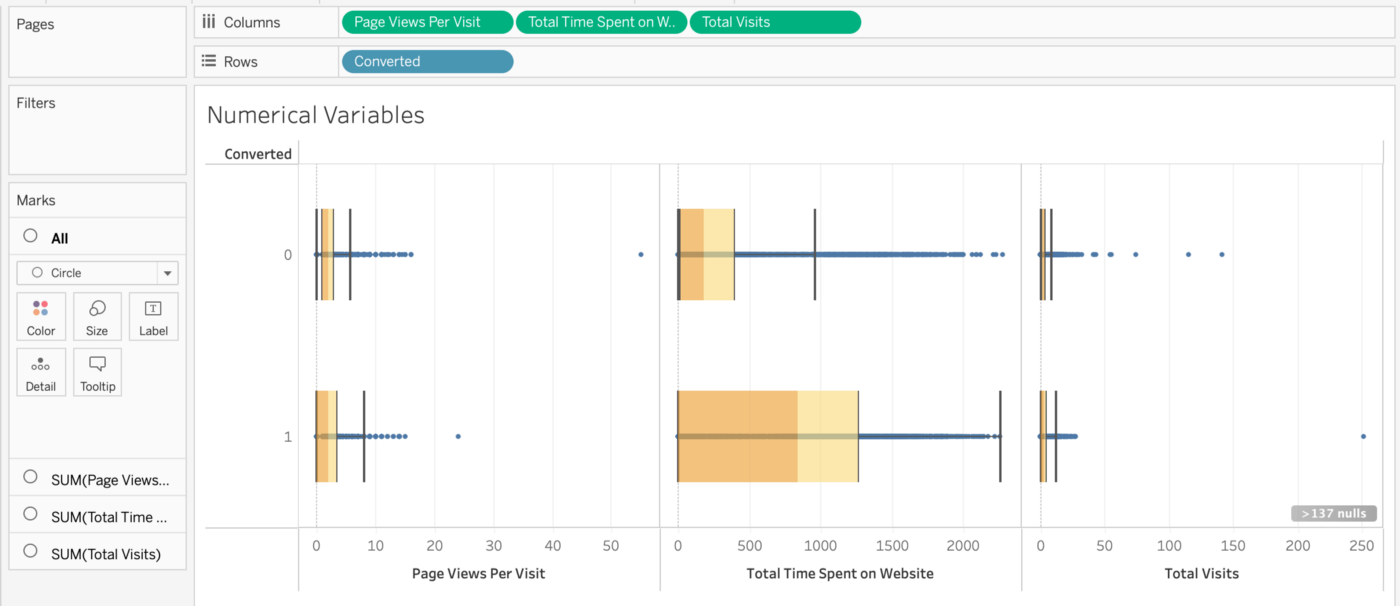
Die numerischen Merkmale “Total Visits", “Total Time Spent on Website" und “Page Views Per Visit" werden nun untersucht. Zur Visualisierung der Datenverteilung werden “Box-and-Whisker"-Diagramme verwendet.
Die durchschnittliche Anzahl der Besuche auf der Website für konvertierte und nicht konvertierte Leads ist identisch. Aus der Gesamtzahl der Besuche kann keine endgültige Schlussfolgerung gezogen werden. Je mehr Zeit Sie auf der Website verbringen, desto wahrscheinlicher ist es, dass Sie konvertieren. Am besten ist es, Verbesserungen an der Website vorzunehmen, um sie für die Besucher einfacher zu machen und ihr Interesse zu wecken. Konversions- und Nicht-Konversions-Leads haben die gleiche Anzahl von Seitenaufrufen pro Besuch. Aus der Statistik lässt sich nicht ableiten, dass konvertierte Leads im Durchschnitt mehr Seitenaufrufe haben als nicht konvertierte Leads. Nun betrachten wir kategoriale Merkmale. Data Scientists achten oft darauf, wie viele eindeutige Werte oder Kategorien in einem Datensatz vorhanden sind. Data Scientists suchen auch nach Kategorien mit sehr niedrigen Werten. Aus welcher Quelle wurde der Lead generiert?
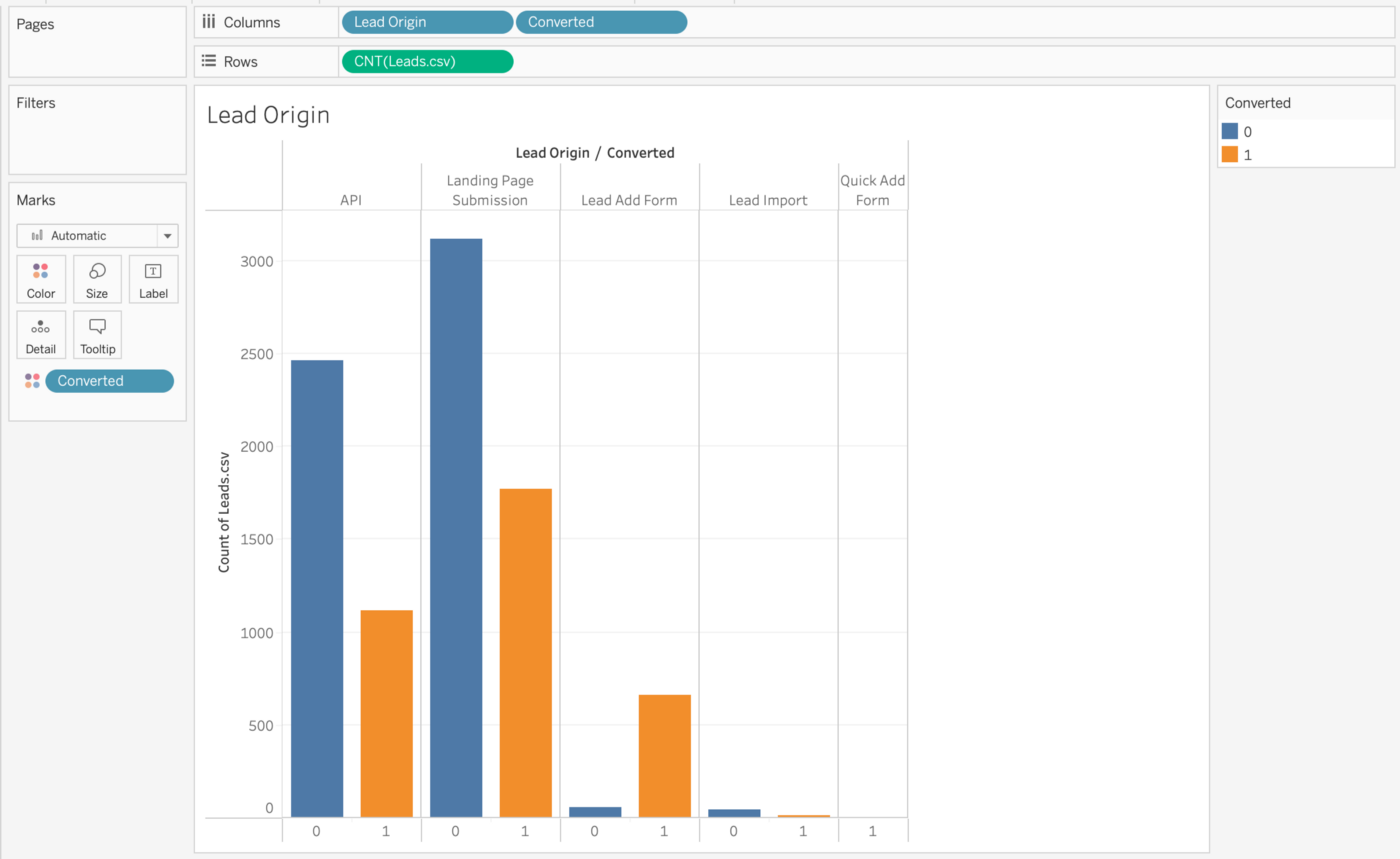
Ein Barchart mit zwei Dimensionen (Lead Origin und Converted) wird verwendet, um die Anzahl der Leads anzuzeigen. Um die gesamte Lead-Konversionsrate zu verbessern, sollten wir uns mehr darauf konzentrieren, die Rate der Leads zu erhöhen, die aus der API- und Landing Page-Übermittlung stammen, und zusätzliche Leads über das Lead-Add-Formular zu generieren. Schauen wir uns nun die Funktion an, ob Nutzer per E-Mail kontaktiert werden möchten.
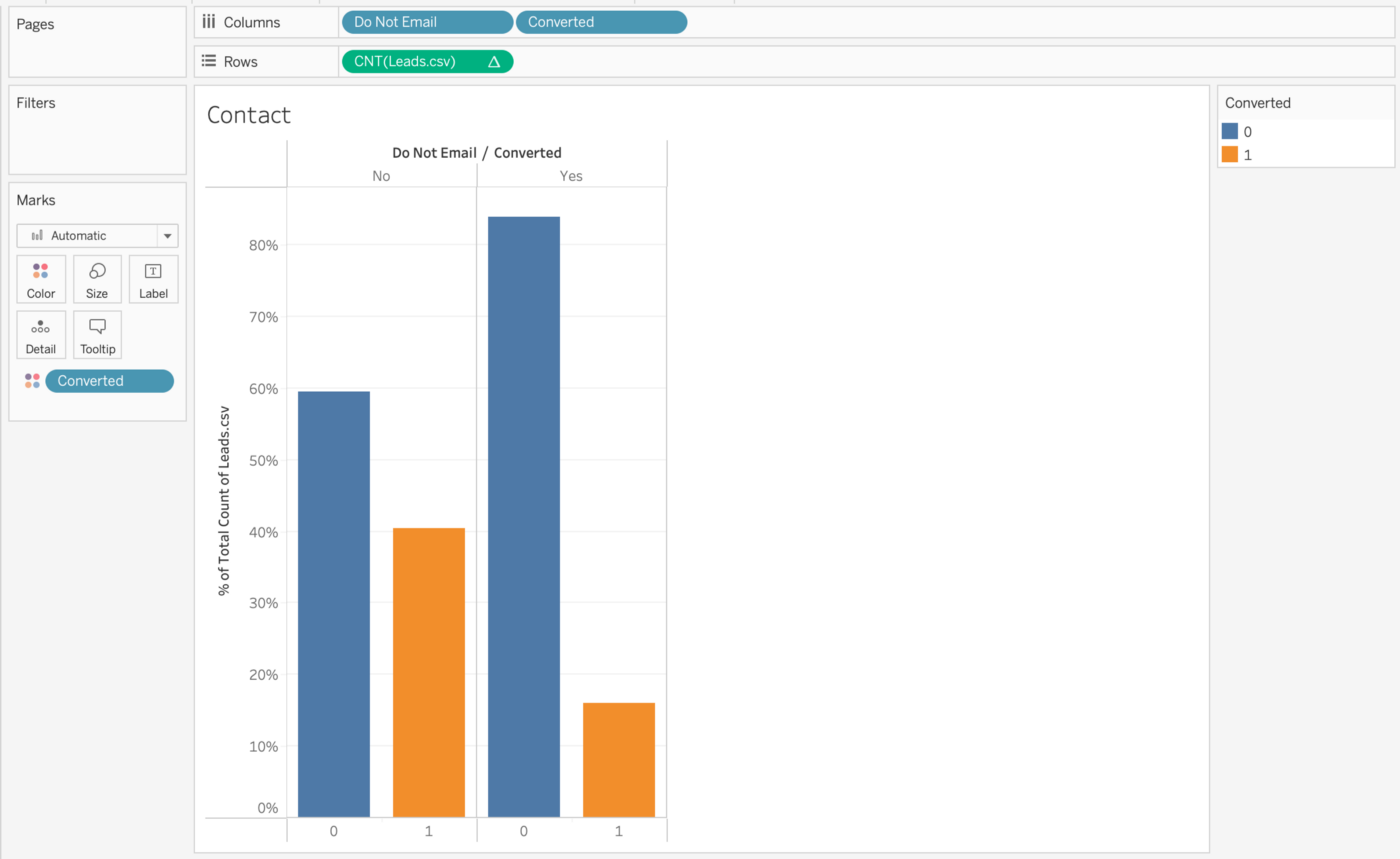
Wir sehen, dass diejenigen, die keine E-Mails erhalten wollen, eine schlechte Konversionsrate haben. Schauen wir uns als letztes Beispiel die letzte Aktivität der Nutzer an.
Die Mehrheit der Leads hat als letzte Aktion ihre E-Mail geöffnet. Bei Leads, die dies als ihre letzte Aktion angegeben haben, hat “SMS Sent” eine hohe Konversionsrate.
Wir konstruieren nun ein Modell, das vorhersagt, ob jeder Lead in dem betrachteten Zeitraum in Zukunft konvertieren wird. Die Grundlage für dieses Modell sind die Daten aus der Vergangenheit, die wir im letzten Abschnitt betrachtet haben. Diese enthalten die Informationen darüber, ob ein Lead konvertiert wurde oder nicht, sodass wir mit überwachtem Lernen arbeiten können. Überwachtes Lernen ist eine Technik der Datenwissenschaft, die aus Beispieldaten mit Kennzeichnungen eine Vorhersage erstellt. Der Data Scientist verwendet die Daten, um ein Modell zu erstellen, das Vorhersagen für ungesehene oder Testmuster erstellen kann. Der Data Scientist stellt sicher, dass das Modell genau ist und entscheidet dann, ob es eingesetzt werden soll. Zur Bewertung des Modells werden nur 70% der Daten für die Erstellung des Modells verwendet. Die verbleibenden 30% werden zum Testen des Modells verwendet, indem eine Prognose erstellt und mit den tatsächlichen Umsatzdaten verglichen wird. Wir verwenden die Modellklasse der logistischen Regression, um ein Prognosemodell zu erstellen. Die logistische Regression ist ein statistisches Modell, das auf der Grundlage einer oder mehrerer unabhängiger Variablen vorhersagt, ob ein Ereignis eintreten wird oder nicht. In unserem Fall ist dies die Frage, ob der Vorsprung umgewandelt wurde oder nicht. Logistische Regressionsmodelle identifizieren die Variablen, die für die Vorhersage, ob ein Lead konvertiert wird, wichtig sind. Die logistische Regression ist eine der am häufigsten verwendeten Data Science-Techniken zur Klassifizierung. Sie misst nicht, wie stark zwei Variablen miteinander verbunden sind, sondern berechnet die Wahrscheinlichkeit, dass eine abhängige Variable (in unserem Fall die Konvertierungswahrscheinlichkeit) bei bestimmten Werten für jede der unabhängigen Variablen auftritt. Dabei handelt es sich um eine Methode zur Schätzung des Vorhersagefehlers komplexerer Modelle, bei der die Daten in Teilmengen aufgeteilt und dann separate kleinere Modelle an jede Teilmenge angepasst werden. Das Modell hat viele Merkmale, aber viele davon sind nicht vorteilhaft für das Modell. Wir werden nun eine Merkmalsauswahl vornehmen, um uns auf die wichtigsten Merkmale zu konzentrieren. Das allgemeine Ziel der rekursiven Merkmalseliminierung (RFE) besteht darin, die Anzahl der Merkmale zu verringern. Der erste Schritt besteht darin, den gesamten Satz von Merkmalen beim Training zu verwenden, und die Wichtigkeit jedes Merkmals wird bestimmt. Die am wenigsten wichtigen Merkmale werden dann aus dem aktuellen Merkmalssatz entfernt. Dies wird rekursiv mit dem reduzierten Satz durchgeführt, bis die erforderliche Anzahl von Merkmalen erreicht ist. Als Ergebnis dieses Prozesses wird ein neues Modell mit einer geringeren Anzahl von Merkmalen erstellt.
Die Implementierung des Trainings und der Bewertung des Modells erfolgt in Python – einer Programmiersprache, die häufig in der Datenwissenschaft verwendet wird. Data Scientists verwenden auch häufig R, aber Python wird immer bekannter, da seine Fähigkeiten im Bereich Data Science wachsen. Wir beginnen mit dem Import der Module, die wir für diese Analyse benötigen: Pandas und sklearn. Zum Laden und Manipulieren wird die Pandas-Bibliothek verwendet. Pandas ist eine ausgezeichnete Wahl für das Munging und die Vorverarbeitung von Daten. Wir verwenden scikit-learn, um die Modelle und Prädiktoren zu implementieren. Dann importieren wir die Daten aus der csv-Datei und teilen die Daten in zwei Teilmengen auf: eine für die Anpassung und eine für die Auswertung. Diese Technik der Datenwissenschaft wird Partitionierung genannt. Dann werden die Daten skaliert. Dies geschieht, um die Eingabewerte für die Algorithmen ausgewogener zu machen, da einige der Merkmale sehr hohe oder niedrige Werte aufweisen können. Nach der Skalierung extrahieren wir die wichtigsten Merkmale und berechnen die logistische Regression. Der Quellcode ist unter: https://gist.github.com/astoeckl/2c3832f8d78ddfc0148b7bf948bdad99#file-leadprediction zu finden.
Danach können wir die Genauigkeit der Vorhersage mit Testdaten bewerten. Diese liegt bei rund 90,5% Genauigkeit.
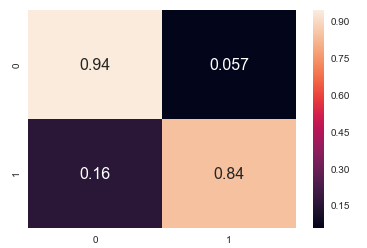
Wir verwenden die Fehlermatrix, um zu untersuchen, wie oft das Modell während der Validierung jede Art von Fehler erzeugt hat. In 5,7% der Vorhersagen wird eine Umwandlung falsch vorhergesagt, obwohl es keine gab. Dies ist ein Wert, der in der Praxis verwendet werden kann, ohne die Genauigkeit wesentlich zu beeinträchtigen. 16% der Konversionsfälle werden nicht erkannt. Auch dies ist ein brauchbarer Wert.
Wir haben die folgenden Dinge über die Daten aus unserem Beispiel herausgefunden: Anhand dieser Daten wurde dann ein Vorhersagemodell für neue Leads erstellt, das eine Genauigkeit von knapp über 90% aufwies.
Die Aufgabe
Der Datensatz von Kaggle
Bereinigung der Daten
Explorative Datenanalyse mit Tableau

Vorhersagemodell
Implementierung in Python
Auswertung mit den 30% Testdaten
Fazit
Über diesen Blog
Hallo, mein Name ist Christian und du siehst hier das Tutorial Template aus dem Wordpress Template Tutorial auf Lernen²
Kategorien
Archiv
- April 2024
- Februar 2024
- Januar 2024
- Dezember 2023
- November 2023
- Oktober 2023
- September 2023
- Juli 2023
- Juni 2023
- Mai 2023
- April 2023
- März 2023
- Januar 2023
- Dezember 2022
- November 2022
- Oktober 2022
- August 2022
- Juli 2022
- Juni 2022
- Mai 2022
- April 2022
- März 2022
- Februar 2022
- Januar 2022
- November 2021
- Oktober 2021
- September 2021
- Juli 2021
- Juni 2021
- Mai 2021
- April 2021
- März 2021
- Februar 2021
- Januar 2021
- Dezember 2020
- November 2020
- Oktober 2020
- September 2020
- August 2020
- Juli 2020
- Juni 2020
- Mai 2020
- April 2020
- März 2020
- Februar 2020
- Januar 2020
Kunden, die uns vertrauen






Als Experten für Conversational AI revolutionieren wir die Art und Weise, wie Unternehmen künstliche Intelligenz sicher nutzen können, um ihre Produktivität zu verbessern. Mit der Entwicklung von CompanyGPT, einer führenden KI-Lösung für den Unternehmenseinsatz, ermöglicht 506.ai eine sichere Nutzung von firmeneigenen Daten und vereinfacht gleichzeitig deren Handhabung durch eine integrierte Bibliothek mit Vorlagen für wiederkehrende Aufgaben.