
In diesem Beitrag zeige ich Ihnen, wie Sie mithilfe von Webanalysedaten eines Online-Shops Kunden gruppieren können. Auf der Grundlage der Ergebnisse können Personalisierungs- und gezielte Marketingkampagnen auf der Website durchgeführt werden. Auf dem Weg dorthin werden wir uns die Daten genauer ansehen (“Explorative Datenanalyse" oder “EDA"), eine erste Verarbeitung der Daten vornehmen, eine Segmentierung erstellen und dann die Cluster präsentieren. Für die Berechnungen werden wir Google Colab verwenden.
Die Daten stammen von der Kaggle-Datenplattform und enthalten Web-Tracking-Daten für einen Monat (Okt. 2019) von einem großen Online-Shop mit mehreren Kategorien. Jede Zeile in der Datei steht für ein Ereignis. Es gibt verschiedene Arten von Ereignissen, wie Seitenaufrufe, Warenkorbaktionen und Käufe. Der Datensatz enthält Informationen über: Die Daten stehen als CSV-Datei als Export aus einer “Customer Database Platform” zur Analyse zur Verfügung. Alle Berechnungen sind in der Colab-Datei enthalten: https://gist.github.com/astoeckl/3c12fedbba2d5e593814fdef230dd81c
"Data Science kann Ihnen helfen, Ihre Kunden besser zu verstehen und ermöglicht Ihnen neue Einblicke in Ihre Kundenstruktur. Nutzen Sie datenbasierte Kundensegmente, um Ihre Umsätze zu erhöhen." PROF. (FH) DR. ANDREAS STÖCKL Senior Expert Marketing Data Science
Für den Monat Oktober 2019 sind über 42 Millionen Datensätze verfügbar.
Über 3 Millionen Menschen besuchten diese Website. Die Kunden kauften über 166.000 verschiedene Artikel.
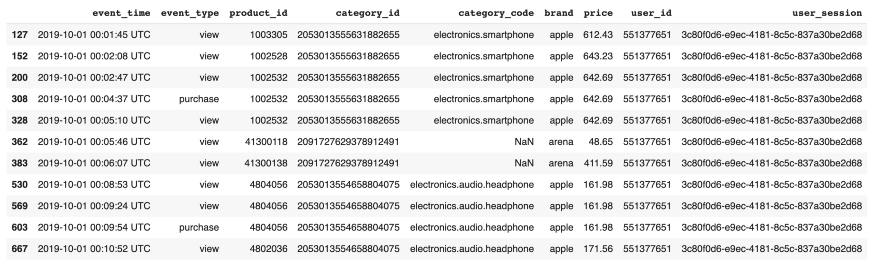
Wir versuchen herauszufinden was eine bestimmte Sitzungsnummer bedeutet, indem wir alle Einträge, die für diese Sitzungsnummer gespeichert wurden, untersuchen und interpretieren.
Um alle Aktionen eines bestimmten Benutzers in diesem Monat anzuzeigen, filtern wir alle Datensätze nach seiner Benutzer-ID.
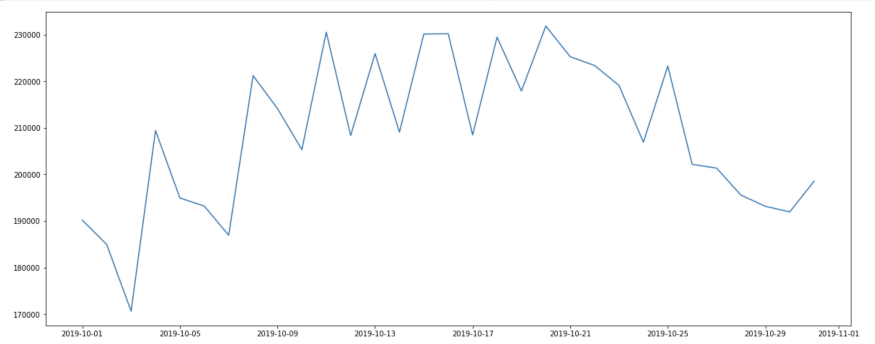
Wie viele Ereignisse wurden bei der Webanalyse an jedem Tag erfasst?
Wie häufig treten verschiedene Ereignisse in den Daten auf, und um welche Ereignisse handelt es sich?
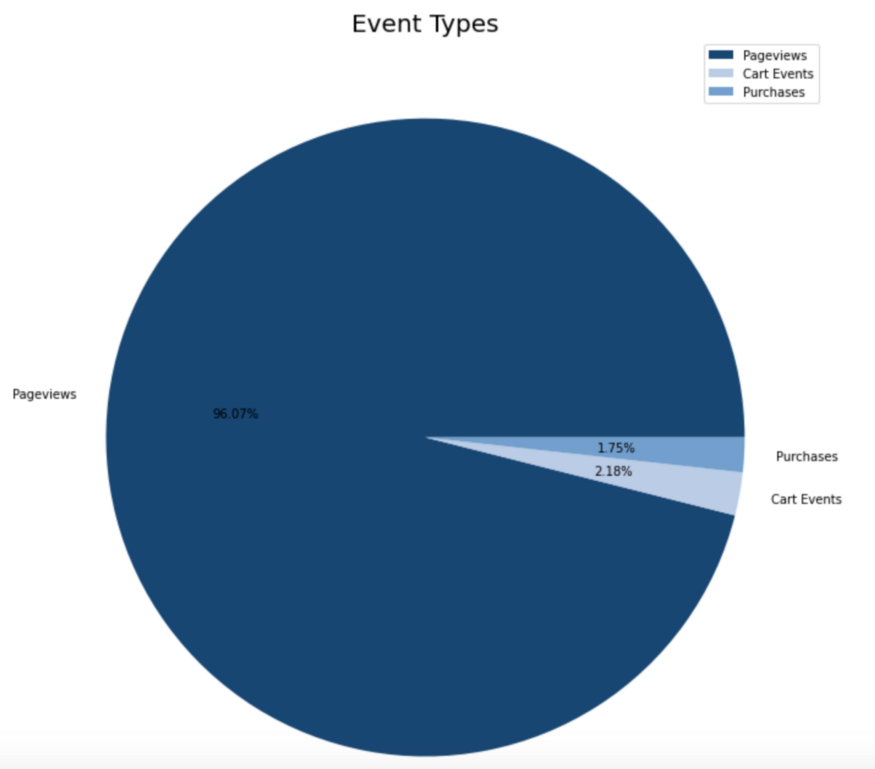
Der Großteil der Informationen besteht aus Seitenaufrufen (96 %), während der verbleibende Teil aus dem Einkaufswagen und den Kaufaktivitäten besteht.
Wir nehmen die wichtigsten Merkmale der einzelnen Besucher und fassen sie in einer Tabelle zusammen.
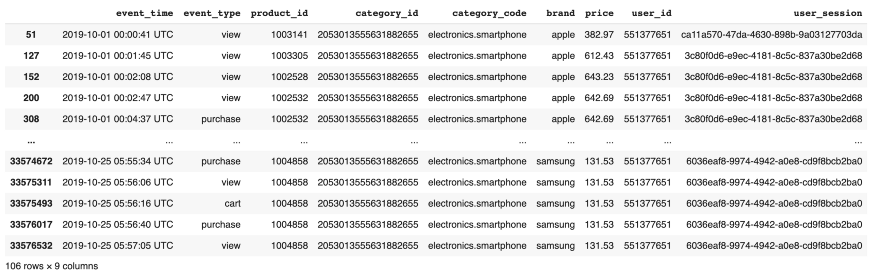
In der folgenden Phase grenzen wir unsere Einkäufe aus den Daten ein, um sie genauer analysieren zu können. Wir speichern das Ergebnis in einer separaten Tabelle.
Wie viele Produkte werden von einem Käufer gekauft? Wie hoch ist der durchschnittliche Einkaufswert pro Käufer? Im Durchschnitt tätigt jeder Käufer etwas mehr als zwei Käufe. Der durchschnittliche Einkaufswert pro Käufer beträgt 773,85 Euro.
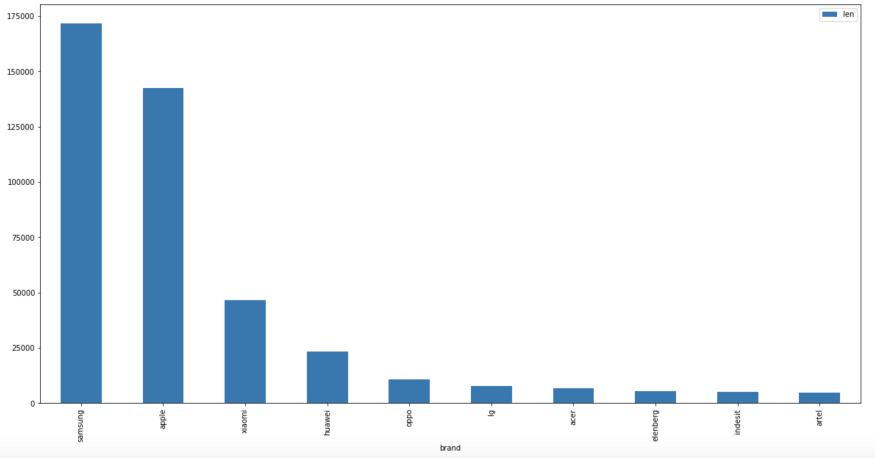
Von welchen Marken werden Produkte gekauft? Sehen wir uns ein Balkendiagramm mit den 10 wichtigsten Marken an.
Für die weitere Analyse gliedern wir die Transaktionen in Gruppen der beliebtesten Marken (die Top 5). Die übrigen werden in einer Gruppe namens “Sonstige" zusammengefasst. Für jeden Kunden ermitteln wir den Anteil der Käufe in den sechs Markenkategorien und speichern sie in der Käufertabelle.
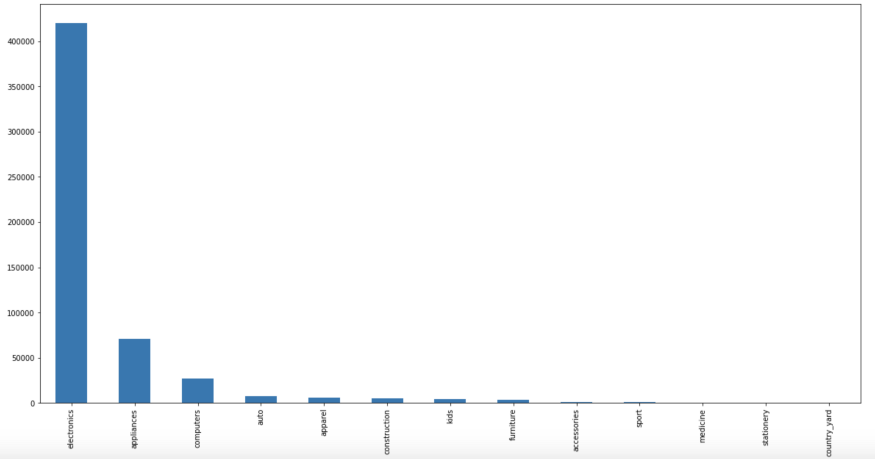
Welche Produktkategorien gibt es? Die Produktkategorie existiert als hierarchischer Code. Wir nehmen die erste Ebene und speichern sie als separates Merkmal.
Insgesamt gibt es 13 Hauptkategorien. Der Anteil des Kaufpreises in jeder der Hauptkategorien wird als zusätzliches Merkmal in die Tabelle der Käufer aufgenommen.
Wir können nun die Kaufmerkmale aller Besucher aggregieren, was zu einer Tabelle mit allen Besuchern und Merkmalen führt. Wir haben also die Daten von 3.022.290 Nutzern, von denen wir jeweils 27 Merkmale gespeichert haben.
Wir werden uns auf die ersten 50.000 Nutzer beschränken, um die Berechnungen und die Visualisierung in Grenzen zu halten.
Bevor wir mit dem Clustering beginnen können, müssen wir die Daten in das richtige Format als zweidimensionales Array bringen.
Um sicherzustellen, dass alle Merkmale auf einer vergleichbaren Skala dargestellt werden, wird die Matrix angepasst, indem sie um den Durchschnittswert verschoben und durch die Standardabweichung dividiert wird.
Der “k-Means-Algorithmus" wird zur Identifizierung der Segmente verwendet. Es handelt sich um eine Art der Clusteranalyse, bei der eine Gruppe von Elementen k-Cluster bilden muss, die im Voraus festgelegt werden. Der “k-Means-Algorithmus" in Daten beginnt mit einer ersten Gruppe zufällig ausgewählter Zentren, die als Startpunkte für jedes Cluster dienen, und führt dann iterative (sich wiederholende) Berechnungen durch, um die Positionen der Zentren zu optimieren. Da wir es mit einer großen Datenmenge zu tun haben, verwenden wir die “Mini-Batch"-Form der Technik, bei der neue Clusterzentren nur einen Teil der Zeit unter Verwendung aller Daten in jeder Iteration berechnet werden. https://towardsdatascience.com/understanding-k-means-clustering-in-machine-learning-6a6e67336aa1
Für einen gegebenen Wert von k berechnen wir das Clustering und suchen dann nach dem optimalen k. Der berechnete Silhouette-Score ist ein Maß dafür, wie gut das Clustering gelungen ist. Je näher der Wert bei eins liegt, desto besser. Er wird verwendet, um zu bestimmen, wie viele Cluster es geben sollte.
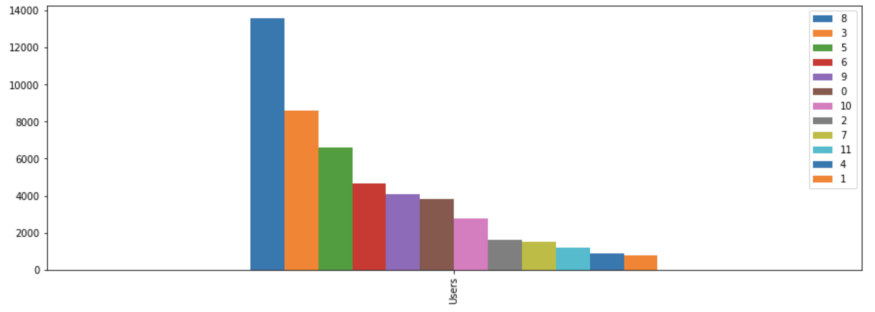
Wir verwenden nun die ermittelte optimale Clusterzahl zur Erzeugung von Clustern. Außerdem müssen wir die Anzahl der Kunden berücksichtigen, die jedem Segment zugewiesen sind.
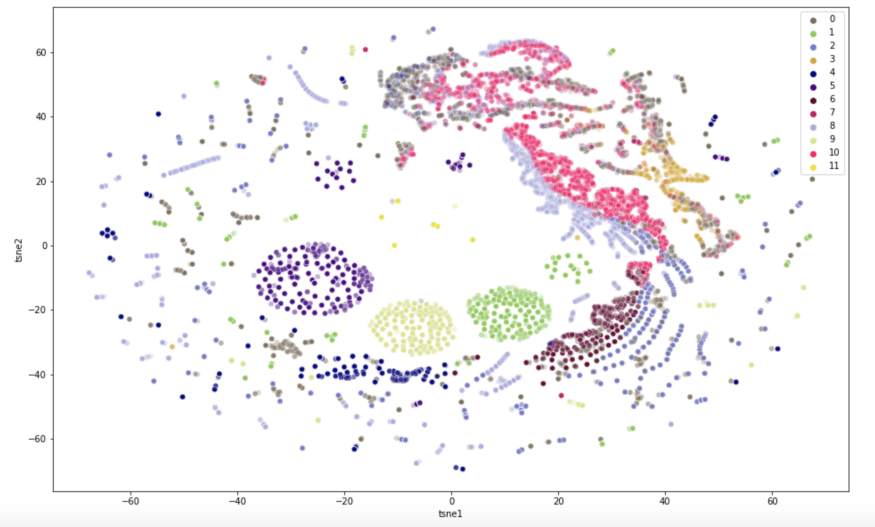
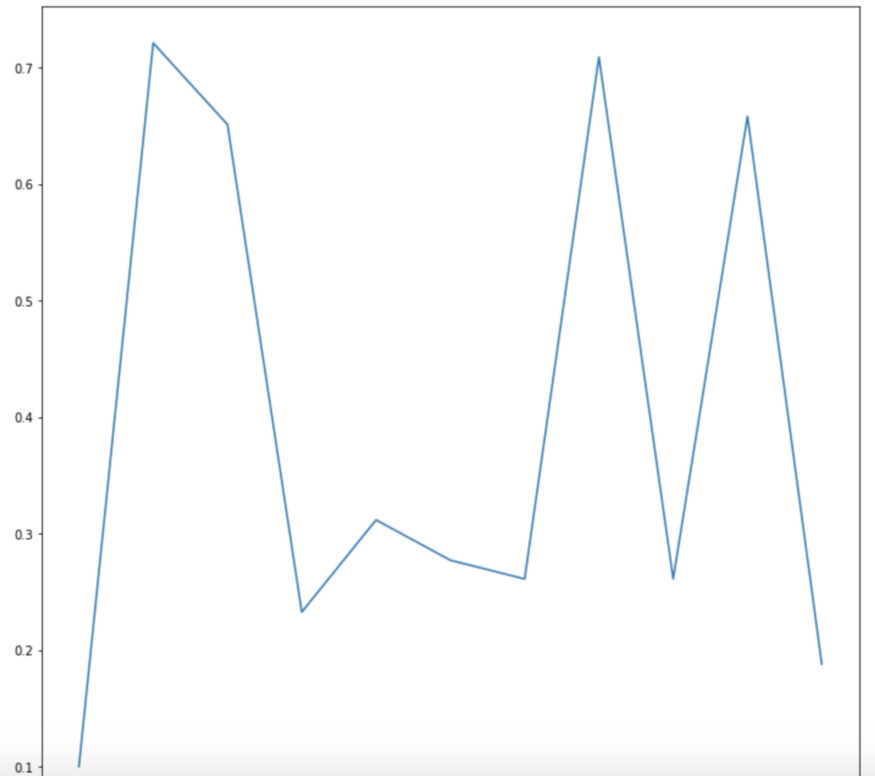
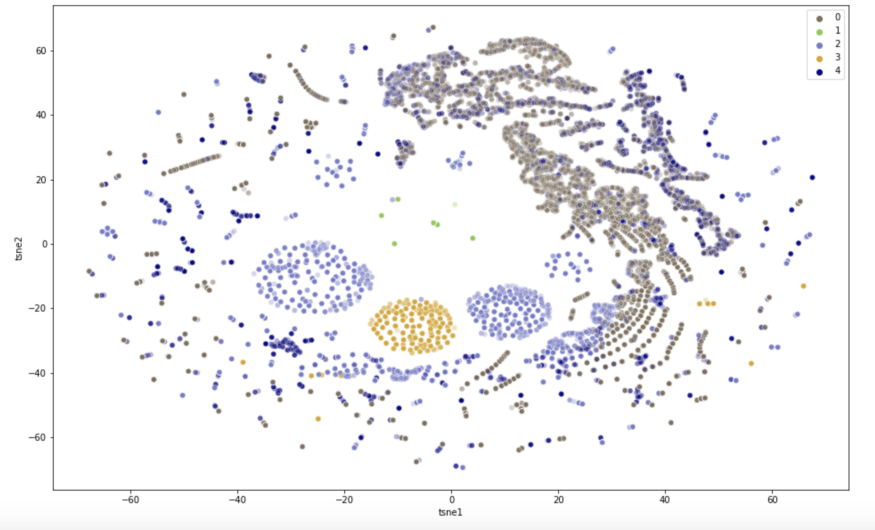
Wir verwenden die Methode “tSNE", um eine Visualisierung der Clusterbildung zu erstellen. t-Distributed Stochastic Neighbor Embedding (tSNE) ist eine Dimensionalitätsreduktionstechnik, die sich besonders für die Darstellung hochdimensionaler Datensätze eignet. Ziel ist es, die Daten durch Dimensionalitätsreduktion in zwei Dimensionen zu projizieren, wobei die Abstände zwischen den Datenpunkten so weit wie möglich erhalten bleiben sollen. https://towardsdatascience.com/an-introduction-to-t-sne-with-python-example-5a3a293108d1
Lassen Sie uns nun eine Visualisierung mit einer weitaus geringeren Anzahl von Clustern ausarbeiten. Es ist wesentlich schwieriger, die einzelnen Regionen in mehrere Teile aufzuteilen.
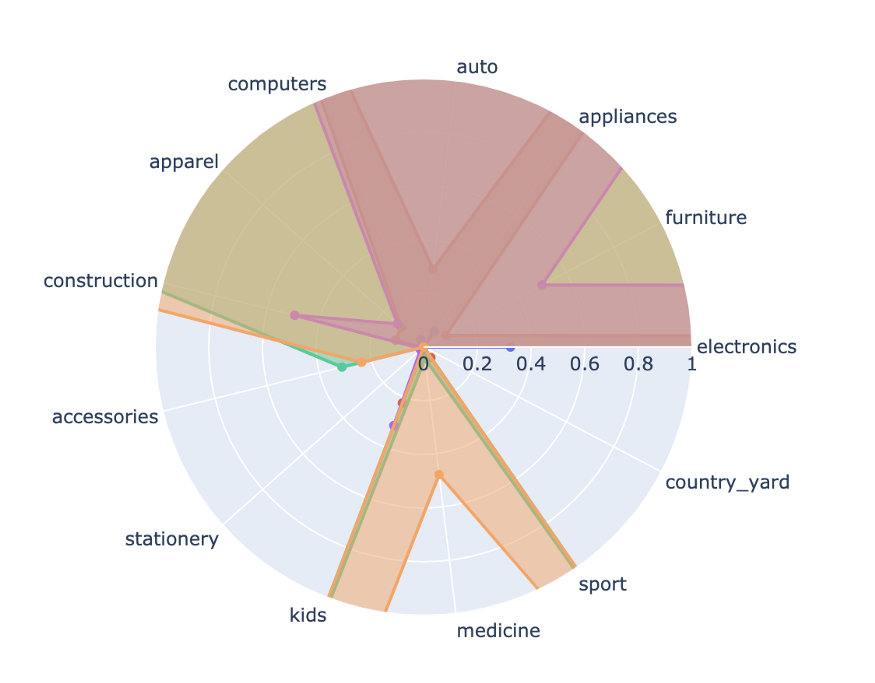
Wir verwenden grafische Darstellungen wie z. B. “Radar-Charts", um die Merkmale der Kategorien für jedes Segment auf einmal zu zeigen, um eine Interpretation der Segmente zu ermöglichen. Dies kann bei der Interpretation der Bedeutung der Segmente helfen.
Zum Beispiel ein Segment mit hohen Kaufanteilen in den Kategorien “Kinder" und “Sport", sowie andere in den Bereichen “Elektronik" und “Gadgets".
Die Daten
Erster Blick auf die Daten

Beispiel Customer Journey
Beispiel Kundenhistorie
Explorative Datenanalyse
Anzahl der Event-Typen
Merkmale der Besucher
Wir filtern die Käufe aus den Aktionen
Schlüsselzahlen zu den Käufen
Beliebtheit der Marke
Produktkategorien
Hinzufügen von Kaufmerkmalen zu den Merkmalen aller Besucher
Begrenzung der Anzahl der Benutzer
Konvertierung in ein Matrixformat für die Berechnung von Clustern
Skalierung der Daten
Berechnung von Kundensegmenten mit unterschiedlicher Anzahl von Clustern
Wie legt man die optimale Anzahl von Clustern ("k-Wert") fest?
Visualisierung von Clustern
Charakterisierung der Segmente
Monat: Juli 2022

Linz, am 13. Juli 2022 – Der E-Commerce und Marketing Data Spezialist Markus Unterweger steigt als Product Owner bei 506 ein und wird ab 1. September die Produktentwicklung für die gesamte 506 Customer Intelligence Plattform übernehmen.
Der 34-Jährige kommt vom innovativen Handelsunternehmen ProMedico aus Graz, wo er die letzten 2,5 Jahre Leiter der E-Commerce und Online-Marketing-Abteilung war und diese maßgeblich ausgebaut hat. Zusätzlich zu seiner großen digitalen B2C Erfahrung war er davor im B2B Bereich bei Pewag, einem der weltweit führenden Hersteller von Ketten, wo er als Leiter im Digital Marketing und für die Einführung der e-Commerce Solution von Pewag zuständig war. In den letzten 5 Jahre konnte Unterweger zudem bereits einige Marketing Data Science Projekte erfolgreich umsetzen.
“Markus verbindet Data Science, E-Commerce Technologien und Online Marketing mit einer herausragenden Neugier und langfristigen strategischen Denken. Damit ist er ein absolut perfektes Match für 506. Wir sind uns sicher, dass wir den gerade begonnenen Erfolgskurs unserer Customer Intelligence Plattform mit Ihm beschleunigen und international ausbauen können”
GERHARD KÜRNER
CEO & GRÜNDER 506
Markus Unterweger ist nicht nur visionärer Treiber der digitalen Welt sondern auch sportlich als österreichischer Jugendmeister im Biathlon und als Ironman Teilnehmer engagiert.
DOWNLOAD PRESSEMITTEILUNG
Bild: (c) 506 Data & Performance GmbH – Gerhard Kürner, CEO bei 506 Data & Performance GmbH
Über 506 Data & Performance GmbH
506 ist ein führendes, Marketing-Data-Science-Unternehmen. Schwerpunkt ist die Visualisierung, Segmentierung und die Aktivierung von digitalen Besucher- und Kundendaten. Mit der KI-basierten 506 Customer Intelligence Plattform und der umfassenden Marketing- und Data-Science-Expertise werden die Userdaten der Kunden in nachhaltige Geschäftserfolge verwandelt.
Bei Rückfragen an 506
Gerhard Kürner
Geschäftsführer
506 Data & Performance GmbH
Mobil: +43 650 4466777
Email: gerhard@506.ai





