
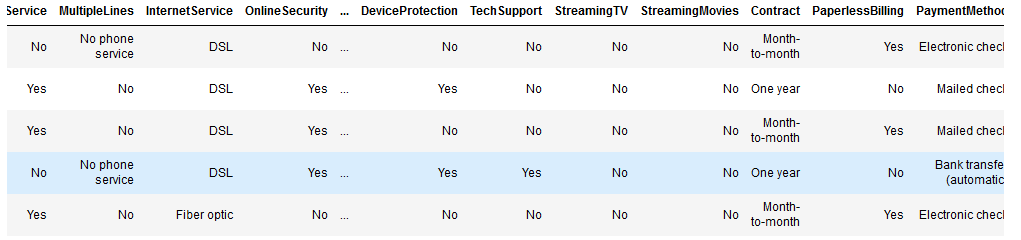
In diesem Artikel verwenden wir Daten von der Datenplattform Kaggle. Der Datensatz enthält Informationen darüber: Schauen wir uns einen Ausschnitt der Daten an:
Jede Zeile steht für einen Kunden, jede Spalte enthält die in der Metadatenzeile beschriebenen Kundenattribute.
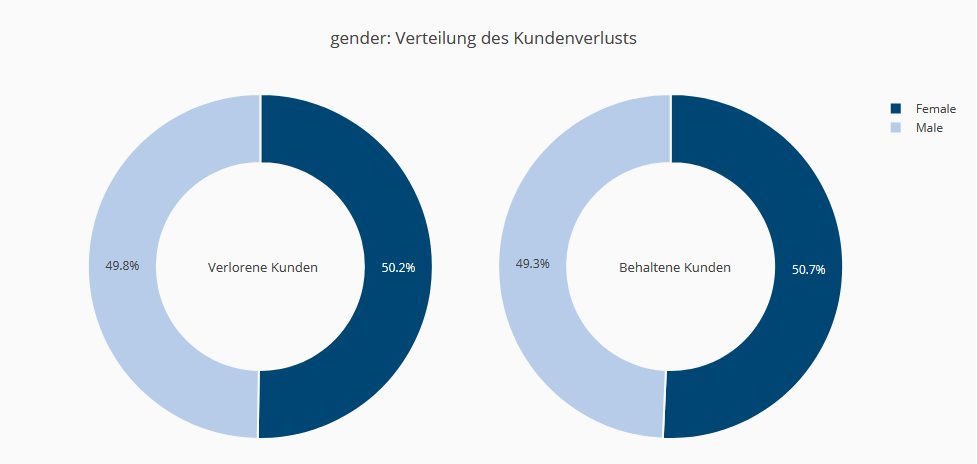
Der erste Schritt des Data Scientists bei der Arbeit mit einem neuen Datensatz besteht darin, ein Gefühl für dessen Gesamtstruktur zu bekommen. Der Data Scientist sollte bei der Erkundung der Daten immer Fragen stellen. Daten sind oft chaotisch und man muss aufpassen, dass man nicht zu schnell voreilige Schlüsse zieht. Die Datenvisualisierung ist ein wichtiger Teil der Datenwissenschaft. In der Explorationsphase stellen Data Scientists Fragen wie “Was sind die interessantesten Variablen?" oder “Wie variieren die Abwanderungsraten zwischen verschiedenen Kundengruppen?". Die Erstellung einiger zusammenfassender Statistiken und Metriken könnte ausreichen, um einen guten Überblick über die Vorgänge in diesem Datensatz zu erhalten. Ein Beispiel: Etwas mehr als ein Viertel der Daten enthält Kunden, die ihren Vertrag gekündigt haben, was für die Analyse ausreichend ist. Bei der Auswertung der Ergebnisse muss jedoch auf diese Unausgewogenheit geachtet werden. Hinsichtlich des Geschlechts ist kein Unterschied zwischen verlorenen und nicht verlorenen Kunden festzustellen.
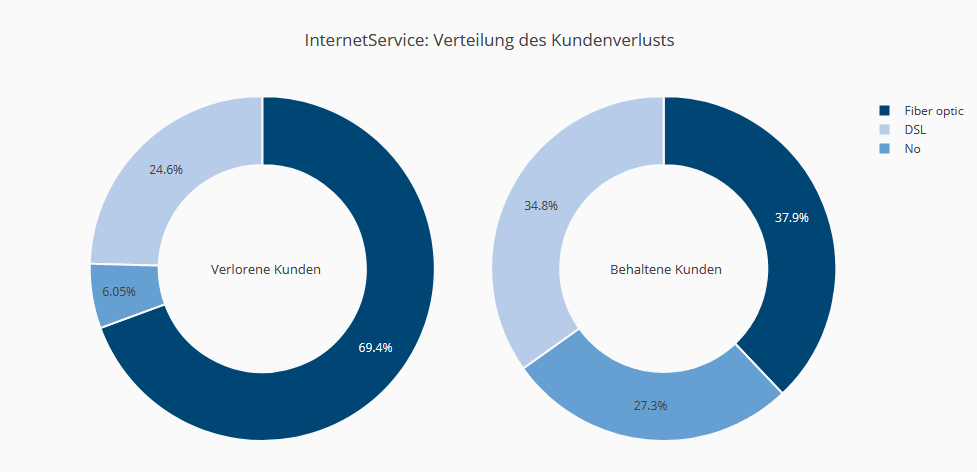
Das Vorhandensein eines Internetvertrages hat einen deutlichen Einfluss – Kunden ohne Anschluss sind weniger wechselwillig, und je höher die Qualität des Anschlusses ist, desto höher ist der Anteil der verlorenen Kunden.
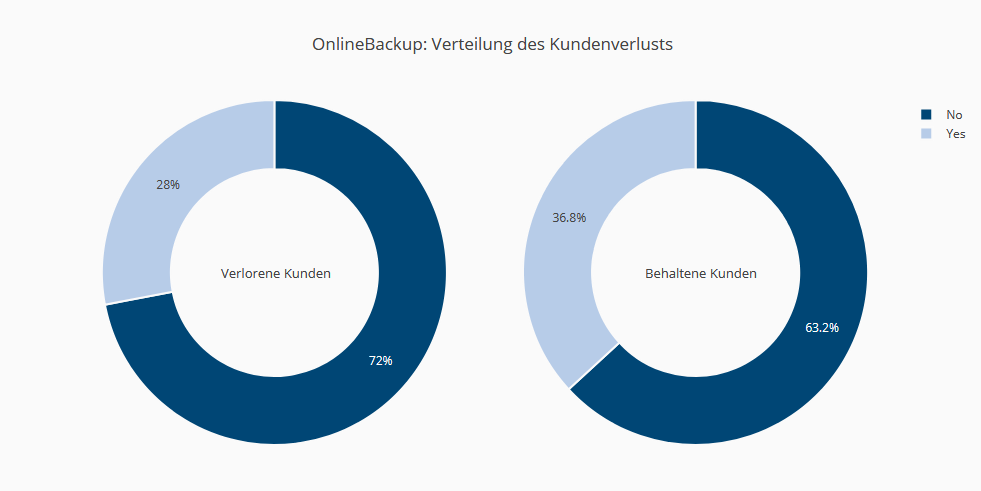
Das Vorhandensein eines Online-Backups hat einen eher positiven Einfluss auf die Kundenbindung.
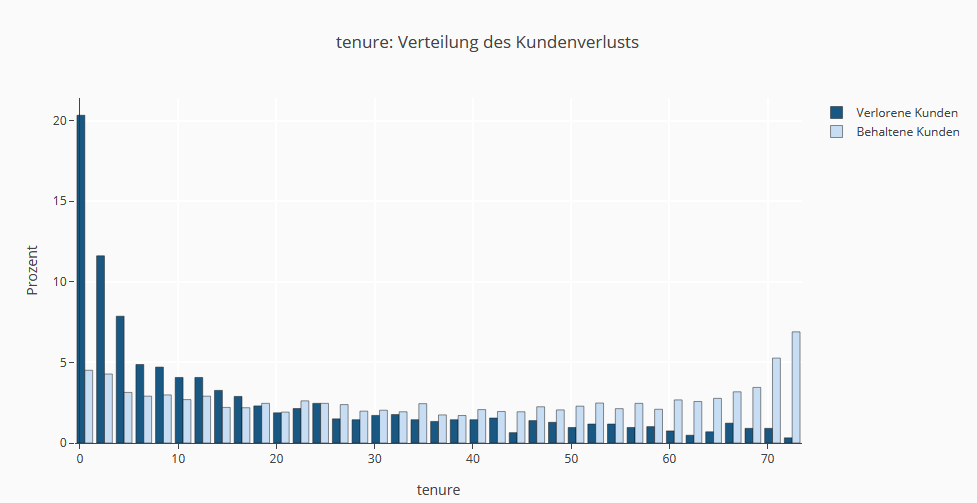
Kurze Vertragslaufzeiten führen zu einer höheren Wechselwahrscheinlichkeit. Kunden, die schon lange einen Vertrag haben, bleiben überproportional treu.
Die Daten und Diagramme enthalten eine Vielzahl weiterer Informationen.
"Data Science kann Ihnen helfen, Muster zu finden und diese Muster zur Vorhersage der Zukunft zu nutzen." PROF. (FH) DR. ANDREAS STÖCKL Senior Expert Marketing Data Science
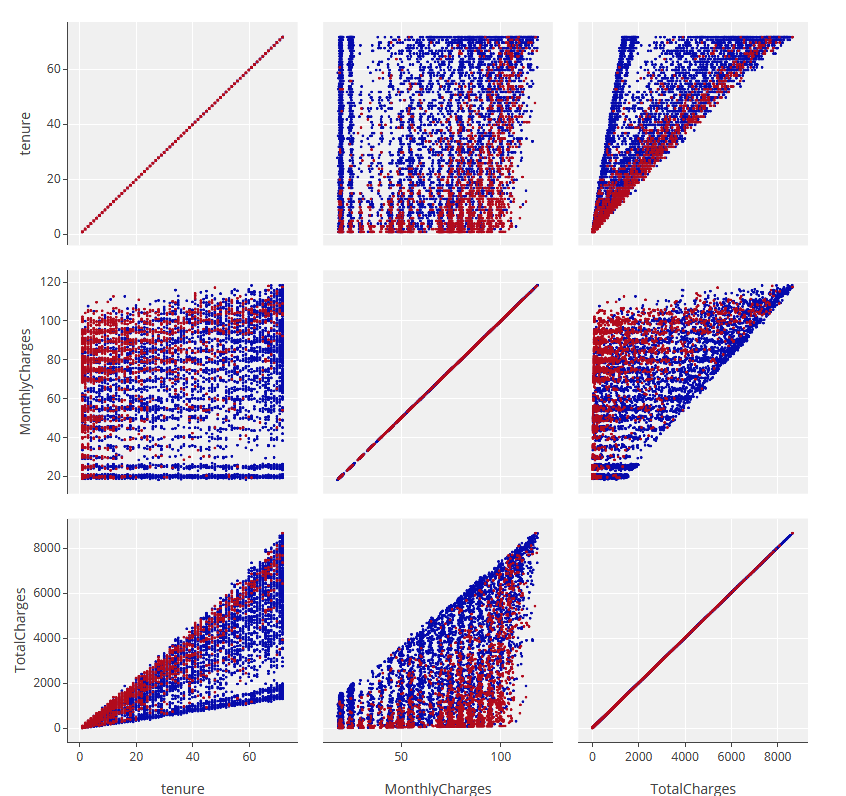
Um einen Einblick in die Zusammenhänge der numerischen Merkmale zu erhalten, erstellen wir eine Matrix mit paarweisen Streudiagrammen. Der Data Scientist hat dann eine sehr einfache Möglichkeit, auf Korrelationen zu prüfen. Jedes Quadrat enthält ein Paar numerischer Variablen aus den Daten. Die Farbe zeigt Kunden mit Abwanderung (rot) und Kunden, die nicht gekündigt haben (blau).
Der Data Scientist kann erkennen, dass einige Variablen eine starke negative Korrelation aufweisen, andere wiederum eine positive. Zwischen der Vertragsdauer und den monatlichen Gebühren lässt sich kein Zusammenhang feststellen, die Punkte sind im Diagramm fast gleich verteilt. Zwischen der Vertragslaufzeit und den Gesamtgebühren besteht ein Zusammenhang, die Punkte sind auf einen Bereich beschränkt. Die monatlichen Gebühren und die Gesamtgebühren füllen eine Halbebene aus. Die Verteilung der Farbgebung zeigt auch hier deutlich die Tendenz, dass Kunden mit kurzen Vertragslaufzeiten und damit niedrigen Gesamtgebühren eher wechseln. Die Achse der monatlichen Gebühren ist überwiegend gleichmäßig mit roten Punkten gefüllt.
Demografische Daten haben zum Teil keinen Einfluss (Geschlecht), aber andere Faktoren wie der Familienstand schon. Zusatzdienste wie Online-Backup, Online-Sicherheit und technischer Support wirken sich positiv auf die Kundentreue aus. Kunden mit schnelleren Internetleitungen, Streaming- oder Filmpaketen haben dagegen eine höhere Kündigungsneigung. Die Zahlungsmodalitäten beeinflussen das Kündigungsverhalten. Die Vertragsdauer und die Bindung sind eindeutig starke Indikatoren dafür, ob eine Kündigung erfolgen wird. Kunden, die schon lange einen Vertrag haben, wechseln nicht so schnell wie Neukunden.
In dieser Darstellung sind alle Korrelationen zwischen den Merkmalen auf einen Blick zu erkennen.
Die positiven Merkmale sind in Rottönen und die negativen in Blautönen hervorgehoben. Jedes Merkmal hat natürlich eine perfekte Korrelation mit sich selbst.
Die Korrelationsmatrix dient nicht nur dazu, Erkenntnisse über die Daten zu gewinnen, sondern ist auch für die Modellierung des später entwickelten Prognoseverfahrens wichtig. Stark korrelierte Merkmale sollten nur einmal in das Modell aufgenommen werden.
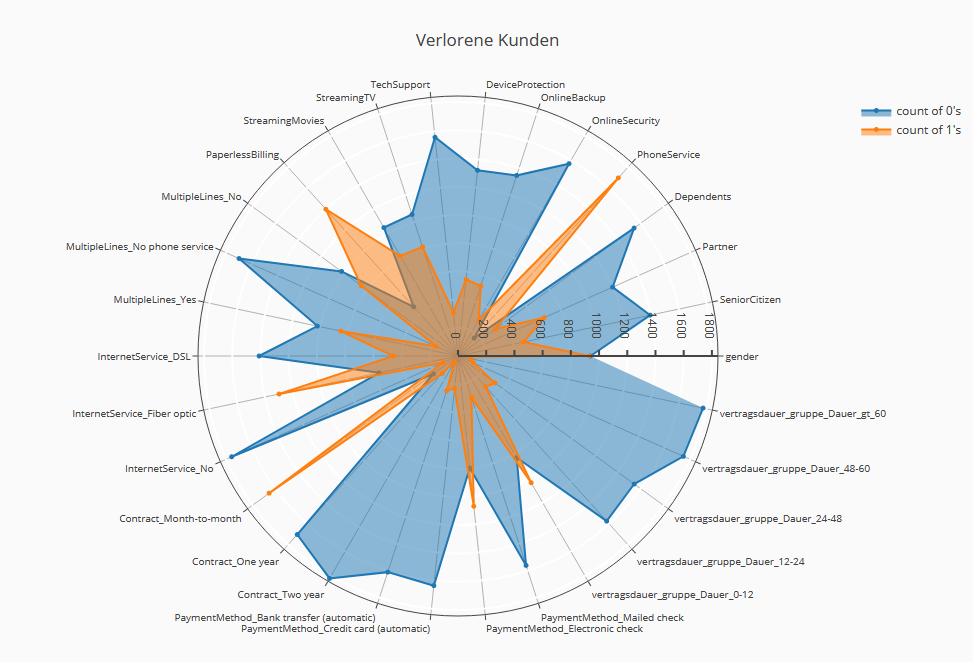
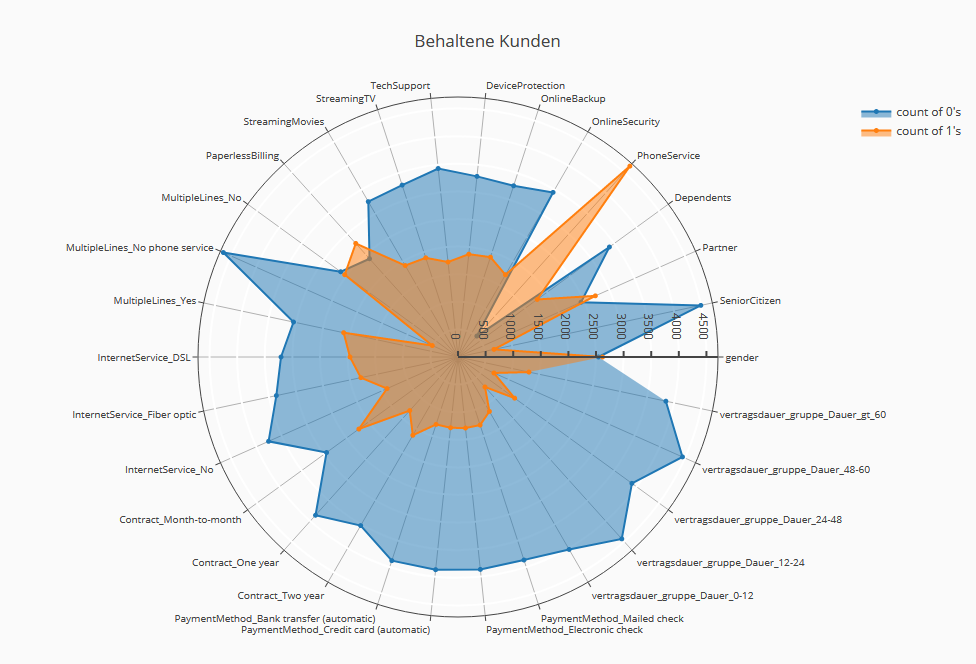
Die Radardiagramme für die beiden Gruppen der verlierenden und der verbleibenden Kunden auf der Grundlage der binären Merkmale zeichnen ein umfassendes Gesamtbild der Unterschiede.
Die Unterschiede in den Ausstattungsmerkmalen Vertragslaufzeit und Zusatzleistungen treten hier ebenso deutlich zutage wie die unterschiedlichen Internetprofile und sonstigen Merkmale.
Wir erstellen nun ein Prognosemodell, das für jeden Kunden vorhersagt, ob er seinen Vertrag im betrachteten Zeitraum kündigen wird. Um das Modell auswerten zu können, werden nur 75% der Daten zur Erstellung des Modells verwendet. Die restlichen 25% werden zum Testen des Modells verwendet, indem eine Prognose erstellt und mit dem tatsächlichen Kündigungsverhalten verglichen wird. Diese stehen uns in den Daten zur Verfügung, die wir zur Erstellung des Modells verwenden. Damit erhalten wir sowohl eine Berechnungsmethode für die Zukunft, die die Kündigungswahrscheinlichkeit auf Basis der Kundenmerkmale berechnet, als auch eine Einschätzung, wie der Kunde in Zukunft reagieren wird.
Zunächst haben wir ein Modell erstellt, das die beiden Kundenklassen mithilfe der Support Vector Machine zuordnet. Die Auswertung zeigt, dass das Modell in 79% der Fälle richtig war. Angesichts der Merkmale und der Komplexität der Aufgabe ist das zunächst nicht schlecht. Die Verteilung der beiden Klassen (gekündigt/geblieben) ist jedoch sehr ungleichmäßig – da nur etwas mehr als ein Viertel der Daten von Kunden stammt, die gekündigt haben –, wodurch die Beurteilung der Anzahl der korrekt vorhergesagten Klassenzuordnungen kein gutes Maß ist. Stellen Sie sich vor, das Modell hätte in unserem Fall vorhergesagt, dass der Kunde nicht gekündigt hat, dann wäre es in über 73% der Fälle insgesamt richtig gewesen, aber immer falsch bei der Vorhersage der gekündigten Fälle!
Daher betrachten wir zwei weitere Kennzahlen, nämlich Precision und Recall, die angeben, wie oft der Prozess bei der Vorhersage einer Kündigung falsch liegt und wie hoch der Anteil der Kunden ist, die der Prozess nicht als Kündigung erkennt. Beide Werte liegen ebenfalls bei 78% und 79%.
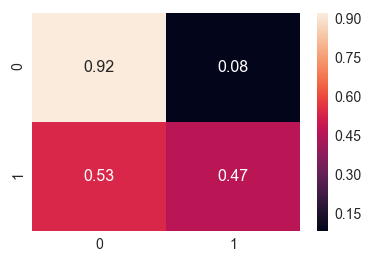
Mit der Fehlermatrix sehen wir uns an, wie oft das Modell bei der Auswertung welche Art von Fehler gemacht hat. Bei 8% der Vorhersagen wird fälschlicherweise ein Abbruch vorhergesagt, obwohl es keinen gab. Dies ist ein Wert, der für die Praxis durchaus geeignet ist.
Allerdings werden 53% der Abbrüche nicht erkannt. Hier muss das Modell noch verbessert werden.
Die folgenden Schritte können zur Verbesserung der Prognosen unternommen werden:
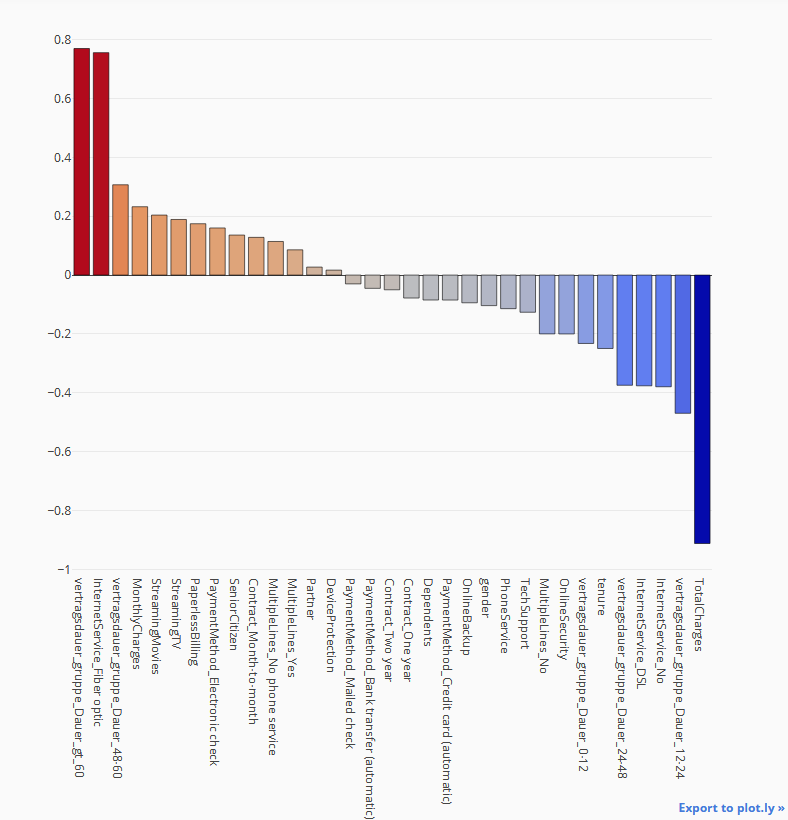
Hier können Sie sehen, welche Faktoren einen starken positiven oder negativen Einfluss auf das Prognoseergebnis haben.
Die Vertragsdauer, d. h. die Anzahl der Stammkunden und die Art des Internetanschlusses sind Faktoren, die einen starken Einfluss haben, mit positiven oder negativen Vorzeichen.
Dank dieser Erkenntnisse konnten wir mit Kundenbindungsmaßnahmen gezielt gegensteuern:
Data Set
Explorative Datenanalyse
Visualisierung des Datensatzes mit Hilfe einer Matrix-Streuungsdarstellung
Zusammenfassung der explorativen Datenanalyse
Korrelation der Merkmale
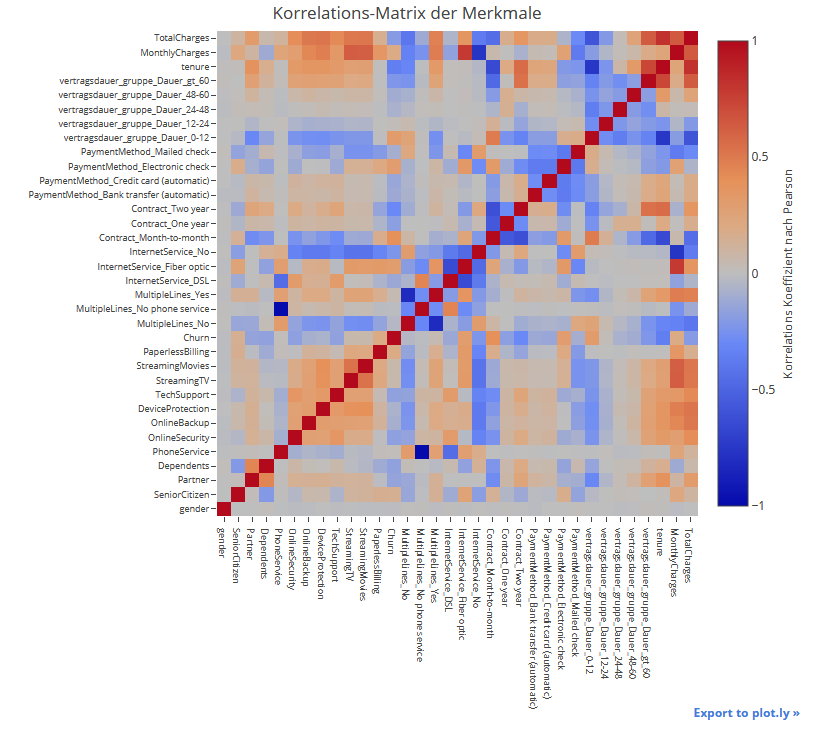
Beispiele für Erkenntnisse aus der Matrix:
Profilanzeige von verlorenen und behaltenen Kunden
Vorhersagemodell
Ergebnisse mit Support-Vektor-Maschine
Weitere Kennzahlen
Fehlermatrix
Potenzial für Verbesserungen
Wichtigkeit der Merkmale
Fazit
Über diesen Blog
Hallo, mein Name ist Christian und du siehst hier das Tutorial Template aus dem Wordpress Template Tutorial auf Lernen²
Kategorien
Archiv
- April 2024
- Februar 2024
- Januar 2024
- Dezember 2023
- November 2023
- Oktober 2023
- September 2023
- Juli 2023
- Juni 2023
- Mai 2023
- April 2023
- März 2023
- Januar 2023
- Dezember 2022
- November 2022
- Oktober 2022
- August 2022
- Juli 2022
- Juni 2022
- Mai 2022
- April 2022
- März 2022
- Februar 2022
- Januar 2022
- November 2021
- Oktober 2021
- September 2021
- Juli 2021
- Juni 2021
- Mai 2021
- April 2021
- März 2021
- Februar 2021
- Januar 2021
- Dezember 2020
- November 2020
- Oktober 2020
- September 2020
- August 2020
- Juli 2020
- Juni 2020
- Mai 2020
- April 2020
- März 2020
- Februar 2020
- Januar 2020
Kunden, die uns vertrauen






Als Experten für Conversational AI revolutionieren wir die Art und Weise, wie Unternehmen künstliche Intelligenz sicher nutzen können, um ihre Produktivität zu verbessern. Mit der Entwicklung von CompanyGPT, einer führenden KI-Lösung für den Unternehmenseinsatz, ermöglicht 506.ai eine sichere Nutzung von firmeneigenen Daten und vereinfacht gleichzeitig deren Handhabung durch eine integrierte Bibliothek mit Vorlagen für wiederkehrende Aufgaben.