Herausragend an der Arbeit sind aber nicht nur die Resultate, sondern auch die Methoden, mit denen dies erreicht wurde. Diese zeigen auch den Weg auf, mit dem weitere Verbesserungen erzielt werden können. Es ist damit zu rechnen, dass analog zur Veröffentlichung von Googles Sprachmodell “BERT” (https://en.wikipedia.org/wiki/BERT_(language_model) ) ein Wettlauf für Weiterentwicklungen unter den Wissenschaftlern gestartet wurde, an dessen Ende Dialoge auf menschlichem Niveau möglich sein werden.
Quelle: www.pexels.com
Dieser Chatbot ist nicht nur auf ein Spezialgebiet optimiert
Auf dem “Preprint” Server “arXiv” kann seit Januar 2020 jeder die Arbeit “Towards a Human-like Open-Domain Chatbot” einsehen und lesen. Beschäftigt man sich näher damit, erkennt man die Dimension des Fortschritts, der hier auf diesem Gebiet erreicht wurde. Wie der Titel schon sagt, wird hier kein Chatbot für ein bestimmtes Wissensgebiet entwickelt, sondern eine Möglichkeit gezeigt, ein System zu schaffen, das quasi Universalwissen ähnlich wie ein Mensch hat und mit dem man sich über jedes Wissensgebiet unterhalten kann.
Viele zum Teil schon gut funktionierende Anwendungen von Chatbots sind auf einen Anwendungsfall oder ein Wissensgebiet fokussiert und mittels speziellen Regeln und dem Einsatz von Machine Learning für “Intent Matching” und “Entity Recognition” aufwändig auf einen Spezialfall hin getrimmt. Auf der anderen Seite sind bisherige Versuche von allgemeinen Chatbots noch sehr mäßig in der Qualität gewesen (z.B. Mitsuku).
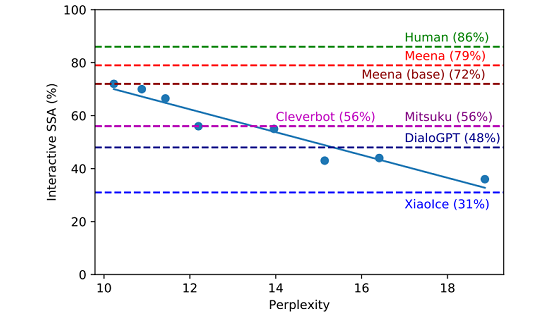
Die Beispiel-Dialoge, die in der Arbeit und in größerer Sammlung auf einer Website dokumentiert sind, wirken beeindruckend. Das auf den Namen “Meena” getaufte System antwortet dabei nicht – wie in bisherigen Ansätzen oft zu sehen war – im Stile eines Politikers mit vagen und ausweichenden Formulierungen, um nur ja keine Fehler zu machen, sondern mit sehr spezifischen Antworten und trotzdem meist korrekt.
Ein Beispiel für einen Dialog mit “Meena”
Mensch: Hi!
Meena: Hi! How are you this fine evening?
Mensch: I’m doing well. it’s morning my time!
Meena: Good morning! What are your plans for today?
Mensch: Get my work done then watch a movie at home in the night
Meena: Sounds fun! What movie?
Mensch: I haven’t decided yet, perhaps an Oscarnominated one. any suggestion?
Meena: I’m not too familiar with recent Oscar winners, but I do know I wanted to see The Grand Budapest Hotel.
Mensch: ah, tell me about that movie!
Meena: It’s from the same director and writer as Moonrise Kingdom. Wes Anderson is pretty well known for making funny, colorful films. I’ve heard it’s pretty good.
Mensch: ha! I’ve searched on the internet and both movies are very colorful!
Meena: I’m looking forward to it. I love colorful movies
Meena kann den Kontext der Unterhaltungen erfassen
Was sofort auffällt ist, dass “Meena” bei einer Antwort auf den vorangegangenen Verlauf der Konversation eingeht, also den thematischen Kontext zuordnen kann und daher passende Antworten gibt. Dies ist eines der am schwierigsten zu lösenden Probleme bei der Entwicklung eines künstlichen Gesprächspartners, der wie ein Mensch wirken soll und wurde hier sehr gut gelöst.
Wie schon oben erwähnt, gibt “Meena” sehr spezifische Antworten je nach Frage und Kontext. Um dies zu erreichen haben die Autoren eine neue Methode entwickelt, um die Qualität von menschlichen und künstlichen Dialogen evaluieren zu können, die nicht nur die Korrektheit der Antworten mit einbezieht, sondern auch wie spezifisch sie sind. Mit dieser Metrik war es dann möglich, “Meena” besser zu evaluieren und optimieren.
“Brute Force” - “End to End” als Lösungsansatz
Noch beeindruckender als die Resultate finde ich die Methoden, mit denen diese erreicht wurden. Die Entwickler wählten eine riesige Neuronale Netz Architektur, eine verbesserte Version des sogenanntes Transformer Modells mit in diesem Fall 2.6 Milliarden Parametern und optimierten dieses dann mit einer gigantischen Menge an Trainingsdaten. Diese in Form von 341 GB an Text vorliegenden Daten wurden aus öffentlichen Dialogen aus den sozialen Medien gewonnen und geeignet gefiltert.
Der Lösungsansatz legt geradezu nahe, die Methode mit noch mehr Daten und noch leistungsfähigeren Modellen zu verbessern und mit weiteren Verfeinerungen der Auswahl der passenden Antworten noch näher an die menschliche Dialogfähigkeit heran zu bringen.
„Wir werden vermutlich noch im Jahr 2020 die ersten konkreten Implementierungen und Anwendungen von “Meena” im Web finden und in nicht zu ferner Zukunft Produkte in unserem Alltag finden, die dies einsetzen. “
PROF. (FH) DR. ANDREAS STÖCKL
HEAD OF CUSTOMER DATA MANAGEMENT