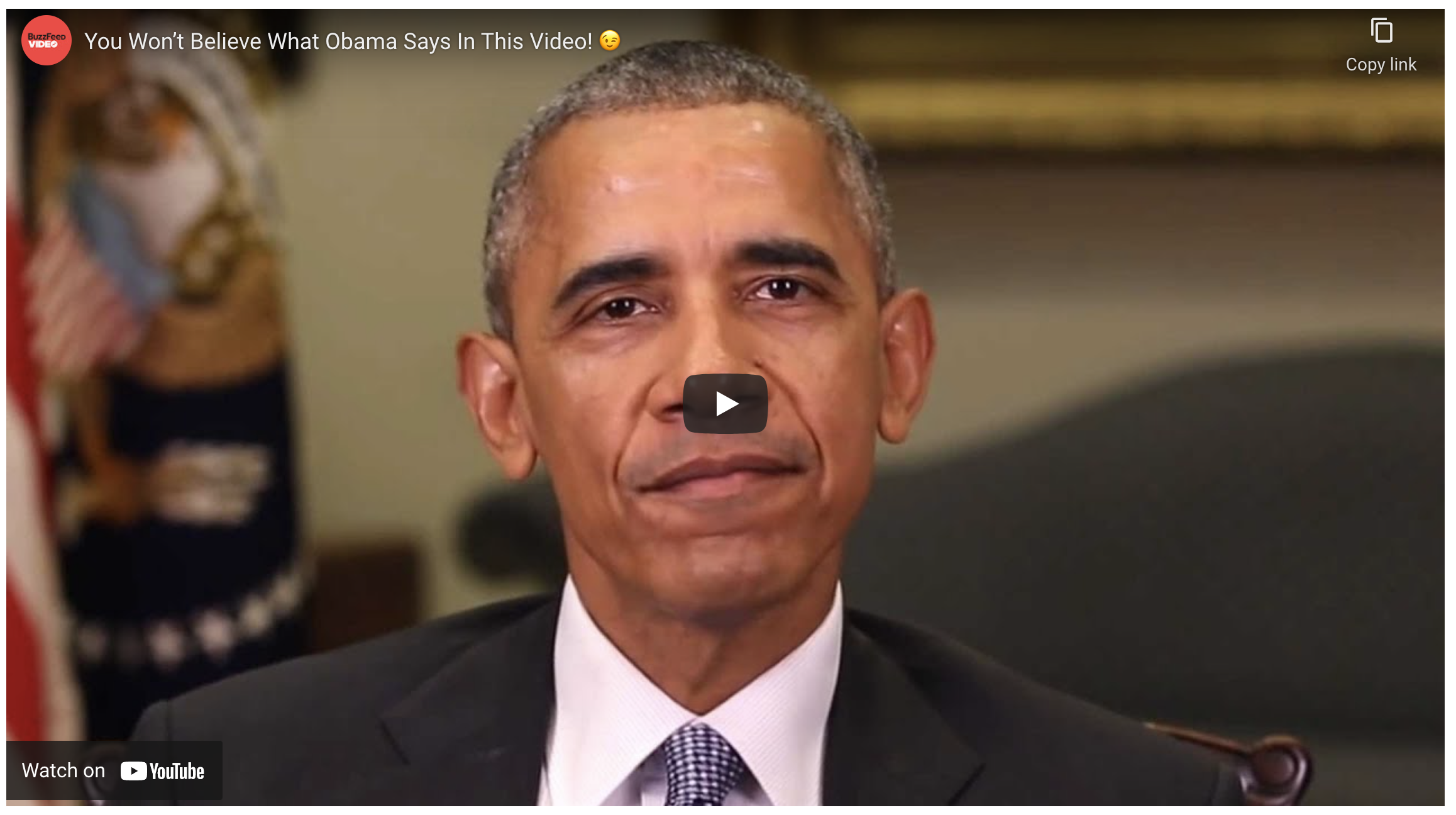
Ein Beispiel
Ein typisches Beispiel, das zeigt, was möglich ist, ist ein Video einer Obama-Rede, die dieser nie wirklich gehalten hat.
Gerade wurde mit www.nuis.tv ein neuer Dienst angekündigt, der Newstexte automatisch mit KI-Unterstützung in Videobeiträge konvertiert. Dies soll dazu dienen, dass User auf einem Smartphone aktuelle Nachrichtenbeiträge nicht mehr lesen müssen, sondern sich diese von einem Nachrichtensprecher präsentieren lassen können.
Um derartiges umsetzen zu können, ist es nicht nur nötig Bilder von Personen künstlich zu erzeugen, sondern auch, diese die Nachrichten vorlesen zu lassen. Die dafür nötigen Technologien zur Verwandlung von Text in Sprache und Lippensynchronisation existieren bereits.
In diesem Blogbeitrag möchte ich zeigen, wie solche digitalen Inhalte erzeugt werden können. Dabei kommen neueste Arbeiten aus der Forschung der Künstlichen Intelligenz zum Einsatz.
Schritt 1) Bild- oder Videomaterial auswählen oder künstlich erzeugen
Für diesen Schritt kann ein Foto oder Video einer Person ausgewählt oder auch künstlich geschaffen werden, die die Aussage tätigen soll. Die Website https://thispersondoesnotexist.com/ erzeugt Fotos von Personen, die nie existiert haben und vermutlich auch nie existieren werden.

(Fake Bild erzeugt mit StyleGAN2. Quelle: www.thispersondoesnotexist.com)
Die Methoden dahinter sind in einer wissenschaftlichen Arbeit (https://arxiv.org/abs/1912.04958) veröffentlicht, und in einem Video (https://www.youtube.com/watch?v=SWoravHhsUU) beschrieben.
Schritt 2) Text der Nachricht schreiben oder generieren lassen
Kommen wir nun zum Erzeugen von Textnachrichten. Die Website https://bellard.org/textsynth/ bietet eine Implementierung des “GPT2 Sprachmodells” von OpenAI (https://openai.com/blog/better-language-models/). Dieses kann genutzt werden, um ausgehend von einem Stück Text diesen weiter fortzusetzen.
Ein Beispiel:
Der folgende Satz aus der New York Times wurde als Start vorgegeben.
“But despite the large drop in new infections since early this year, the U.S. death rate remains at nearly 1,500 people every day.”
Die Story wurde wie folgt fortgesetzt:
“The CDC estimates that 1.6 million Americans die annually from infections linked to SARS. The virus causes fever, respiratory illness, weakness and confusion. It can cause diarrhea, kidney and liver failure and is believed to have caused more than 300,000 deaths worldwide. The Ebola outbreak is the most severe since the devastating 1976 SARS outbreak that killed at least 15,000 people.”
Die Story liest sich wie ein echter Newsbeitrag, jedoch entsprechen die Fakten nicht der Realität. Dies zeigt, dass Fact-Checking Techniken immer bedeutender werden. Nur weil etwas echt klingt, bedeutet das nicht, dass der Inhalt echt bzw. korrekt ist.
“Ich hab es mit eigenen Augen gesehen” kann in der heutigen digitalen Zeit kaum mehr als stichhaltiges Argument gelten.
Andreas Stöckl
HEAD OF CUSTOMER DATA MANAGEMENT
Schritt 3) Erzeugung der Audioaufnahme aus dem Text
Möchte man den Text nun von der Person gesprochen haben, benötigt man eine Tondatei mit der Rede – aber nicht nur mit irgendeiner Stimme gesprochen, sondern mit der Stimme der gewünschten Person. Dies leistet das NVIDIA’s Flowtron Model (https://github.com/NVIDIA/flowtron). Es generiert gesprochene Texte, die kaum von echten zu unterscheiden sind. Hier kann die Stimme des Sprechers durch ein Muster vorgegeben werden.
Schritt 4) Erzeugung des lippensynchronen Videos
Mit Wav2Lip (https://github.com/Rudrabha/Wav2Lip) kann schließlich auch das Problem der Lippensynchronisation gelöst werden. Die Software generiert realistische, sprechende Gesichter für jede menschliche Sprach- und Gesichtsidentität.
Das Video https://www.youtube.com/watch?v=0fXaDCZNOJc zeigt die Resultate des Verfahrens.
Fazit
Kombiniert man nun all diese Technologien, so erhält man ein System, das nicht nur einen Text nach Vorgaben erfindet, sondern diesen auch von einer beliebigen Person (real oder erfunden) als Video aufsagen lässt. Das zeigt, dass man sich nicht mehr sicher sein kann, ob ein Video, das man auf Social Media gesehen hat und in dem eine Person eine Aussage tätigt, nicht vollständig erfunden ist.